









DeepSeek-R1ģ�͑{����Խ�����������c�_Դ���ԣ���������ȫ���˹�������δ����֡�Ȼ�����I������u�y�����@ʾ�_Դ��DeepSeek-R1�MѪ��ģ�ʹ��ڰ�ȫ�̰壬�@�Ƽs��DeepSeek-R1���H��ؑ��á����⣬DeepSeek-R1�MѪ��ģ�ͅ��������漰�Ӽ��g�࣬�����{�YԴ���Ĵ��g�T���ߣ�����Ї�ͨ�����ƌW�c�˹������о�Ժ��������������m���Կ��y���ڽ��������DeepSeek-R1�MѪ�氲ȫ����ģ���аl�����F����ģ��ԭʼ����������ͬ�r����ȫ�����@��������
Ŀǰ��DeepSeek-R1�MѪ�氲ȫ����ģ�������ģ������Ԫ��ģ�ͼ����һ�T�����Ͼ�Ԫ��MaaSƽ�_�������_��ԇ�ã��ṩ�ջ��ٳɵĴ�ģ���_�l���ù��ߡ�
��ȫ������ģ��DeepSeek-R1-Safe�Ͼ�Ԫ��MaaSƽ�_
��ȫ����ǰ���HЧ������
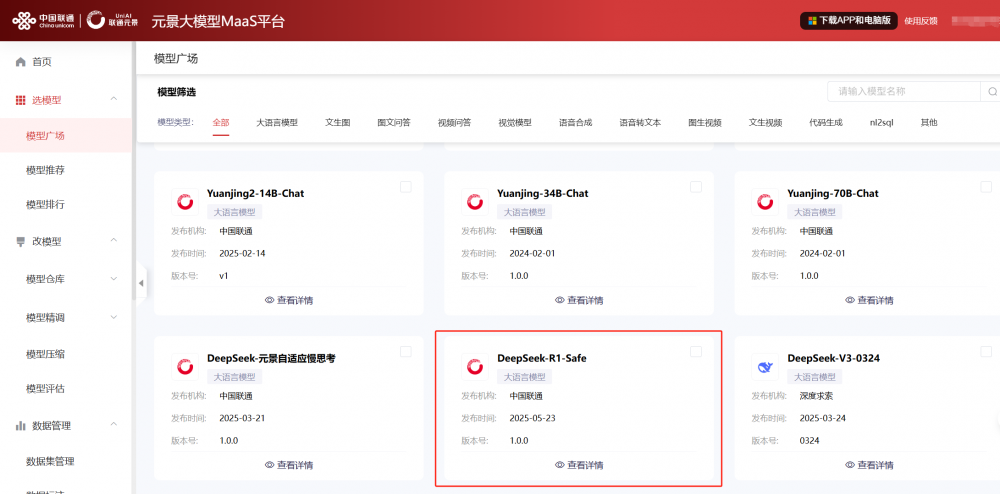
�Dʾ��չʾ��DeepSeek-R1��ȫ����ǰ�������������Կ��������漰��������rֵ�^�ȷ���Ć��}��DeepSeek-R1��ȫ�����涼�ܽo������ȫ��������������x���ărֵ�^�Ļش�

����ԭʼ�����������@��������ȫ����
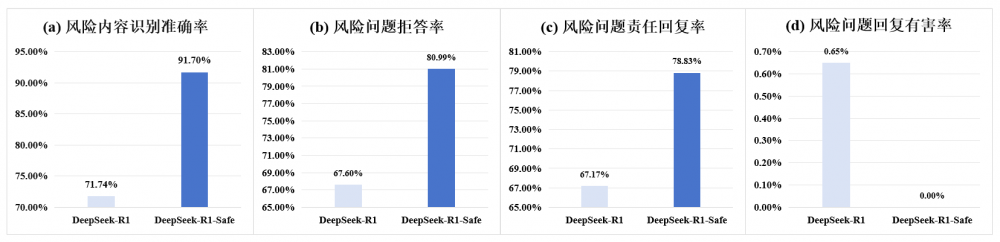
�Ї�ͨ���������аl�����İ�ȫ�u�y����CHiSafetyBench��ԭ��DeepSeek-R1���䰲ȫ�����汾�M�а�ȫ�����u�y��ԓ�����u�y�΄շ֞�ɴ���ͣ��L�U�����R�e���x���}�c�L�U���}�ܴ�Ć����}��ͬ�r�����u����ȫ������ģ�͵���������������MATH-500��GPQA��LiveCodeBench��������������ʌ�ģ���M���yԇ�����^�찲ȫ����������DeepSeek-R1������������Ӱ푡�
��ȫ�����u�y�Y��
���������u�y�Y��
���u�y�Y����Ҋ���ڌ�DeepSeek-R1�M�а�ȫ�{������ģ�����L�U�����R�e�ʴ_����������20%�����L�U���}�ľܴ���������13%��؟�λ؏���������11%���к��؏͔�������0�����F�؏���ȫ�o����ͬ�rģ���ڔ��W��߉�����a���ɵȷ������������δ�����@Ӱ푡�
��ȫ��������
ᘌ�DeepSeek-R1�İ�ȫ�Ԇ��}���Ї�ͨ�����ƌW�c�˹������о�Ժʹ�����������Č��ð�ȫ˼�S朔�����ģ���{���ڇ��a��ƽ�_�ό�DeepSeek-R1�MѪ���M���{Ӗ�������У���ȫ���������Ƀɲ��ֽM�ɣ��۽���ҕ���֙���P�I�I��İ�ȫ�����Լ�ͨ��˼�S����픵������ȫ�����@����չģ�Ͱ�ȫ�ďV���c��ȣ���ȫ��ظ��w���ڵİ�ȫ�L�U������˼�S����픵���ļ���ɴ_������ģ�Ͱ�ȫ���ܵ�ͬ�r��������ԭʼ�����������Ķ����F��ȫ�c����������ƽ�⃞����
����DeepSeek-R1ģ������Ӗ���nj��FDeepSeek-R1��ȫ������P�I�������Ї�ͨ�����ƌW�c�˹������о�Ժ���ڴ��������γ�Ԫ����ģ��MaaSƽ�_�ϵġ���ģ�͡����ߣ������˶˵���ģ�ͷ��հ�ȫ����朣�MaaSƽ�_�����P�I�M��RAG�������w���@�����Ų��Ї�ܛ���y�u���Ĵ�ģ�Ͱ�ȫ�Ԝy�u4+����������J�C��
δ�����Ї�ͨ�����m���MDeepSeek-R1ģ�͵İ�ȫ�о�����������ģ�Ͱ�ȫ�����������u�y���ʣ�����I����m���_�����о��ɹ����Ї�ͨԸ�c�ИI���y�֣���ͬ������ģ�͵İ�ȫ�������������ٴ�ģ���ջݻ��M�̣����˹������x��ǧ�а٘I���{�o����
ģ���_Դ��ַ���£�
GitHub��https://github.com/UnicomAI/DeepSeek-R1-Safe
ħ�https://www.modelscope.cn/models/UnicomAI/Unichat-DeepSeek-R1-Safe-bf16
https://www.modelscope.cn/models/UnicomAI/Unichat-DeepSeek-R1-Safe-w8a8


































