




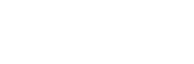





���I�u�y���
�Ԝy���
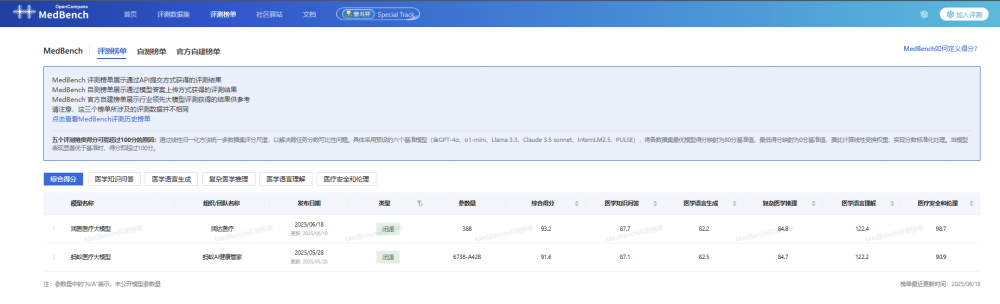
6��18�գ��t����ģ���u�yƽ�_MedBench�l���°��u�y��Σ����_�t���c�A�����ڱP�Ŵ�ģ�̈́����аl�ĝ��t�t����ģ���ڌ��I�u�y��κ��Ԝy������ٴε�픣��քe��96.4�ֺ�93.2�֘s���p�Ϲ�܊��
�Ȟ鲚Ŀ���ǣ����t�t����ģ�����Ԝy��ε��t�W֪�R�����t�W�Z�����ɡ��t�W�Z�����⡢�t����ȫ�����Ă��S�ȷքeȡ��91.2��85.1��123.1��106.6�ă����ɿ����څ��u�F��ҵĸ�����Ó�f�������ڌ��I�u�y����У�ģ��ͬ�ӱ��F���ף����t�W֪�R���𡢏��s�t�W�������t�W�Z��������t����ȫ���������u�y�зքe�@��87.7��84.8��122.4��98.7�ij�ɫ�ɿ����s�ǰ��ף��ɞ酢�u�t����ģ���е�ٮٮ�ߡ�

���t�t����ģ����2025�A���_�l�ߴ�����ܲ�Ŀ
6��20�գ���2025�A���_�l�ߴ����HDC���ϣ��A�鳣�ն��¡��A����CEO��ƽ�������}���v���e�ἰ���t�t����ģ�ͣ��������t��AI�I��ȡ�õ�ͻ�����Mչ�o��߶��u�r����ƽ�������v��������MedBench�����u�y�Y������ֿ϶��˻��ڱP�Ŵ�ģ�͏������������ͨ�^�t���I�I��Ӗ����ĝ��t�t����ģ����չ�F�ļ��g�����̈́��³ɹ����@һ�ɾͲ��H�w�F�˱P�Ŵ�ģ�͈F����t��AI����Č��I�����������@�˱P�Ŵ�ģ������ͨ���˹����������ď��������Mһ���_���˝��t�t����ģ�����ИI�ȵ��I�ȵ�λ��Ӱ�����
MedBench���������t����ģ�͙����u�yƽ�_�����Ϻ��˹����܌���ҡ��Ϻ��Д����t�W���������϶�ҙC�����죬�ѳɞ�ȫ���t��AI�I����Ҫ���˜�֮һ��Ŀǰ��ƽ�_����Ӌ�u�yȫ������t����ģ�ͣ����t�W֪�R�����t�W�Z�����ɡ����s�t�W�������t�W�Z�����⡢���t����ȫ�͂������S�ȣ��ṩ���^�ƌW��ģ�������u����
���t�t����ģ����MedBench�u�y�Дث@�ѿ������չʾ�˱P�Ŵ�ģ�͈F����t��AI�I�����ļ��g�e�ۺ�Խ�Ą���Ӳ�������@һ�T���LjF������t�W�I���ģ���аl����Ҫ��̱���Ҳ�LjF����t�W��ֱ�I����������mͻ�Ƽ��g߅��������C����
���A��P�Ŵ�ģ��L0�ӵĻ��A�ϣ��P�Ŵ�ģ�͈F�ʹ����ǧ�|�����|������Ӣ���t�W�īI���t�Wָ�ϡ���������ǧ�f�����t�������n����֪�R�D�V�Ȕ����M��Ӗ���������˝��t�t����ģ���t�W֪�R���䣬�@������ģ�͵��t�W���I���_�c����������
����ʹģ���܉ʲ��t�������еď��sģʽ�c�����Pϵ���@�������t�W֪�R�����Z�����ɺ����⡢���s�t�W�����ȸ��A�������P�Ŵ�ģ�͈F�����˻��ڶ������w���t�W�����ϳɹ����������M���g�����������������w���Ȍ��}Ŀ���t�W�I���y�ȡ��}�͵ȾS���������������ӛ��ģ�K�ٻظ����ƶȆ��}ʾ���M��֪�R�A�ᣬ�ԄӘ���������ģ�ͲɘӺ���Ϣ�����Ĕ����ϳɹ���������˼�����wͨ�^�u���ɘӔ���һ���ԡ����}��ɶȡ��؏��L��������Լ���Ϣ���ϵĺ������c�����Եȣ��������ϳɹ���������������h���Ƅӹ��������m�������M���Ķ��Mһ�������t�W�����|����ͬ�r������������Ĺ�������ӛ��ģ�K�б��棬���෴�����������������w�����F�����M�W����
�����ϳɹ����������M���g�静�t�t����ģ�ͺ�Ӗ���A�κϳ�֪�R��䡢���_�ʴ_��Ҫ��ȫ�桢߉�����ĸ��|��Ӗ�����������Hģ�͌W����֪�R�����W���ˡ������������\�ࡱ�������_���ȸ��A�J֪���ܣ�ʹ���t�t����ģ�ͳɞ鶮�t�W����˼���������_���ИI�I�ȵ��t������ģ�͡�
�P�Ŵ�ģ�������t��AI�ď�����A����������ǰ�ص��t�W����Ӗ�����g�����Ĵ���ģ���_�l�������Ƅ��t���ИI�~�����ܻ������ʻ������Ի��č��r�������S���g���������͑��È�����ȔUչ���P���t������ģ�͌��ɞ������t�����B���P�I���棬���H���tԺ���ֻ��D���ṩ���ń������������׃����y�t�������|����Ч���c�ɼ��ԡ��P�Ŵ�ģ�ͼ������t�W�����ϼ��gͻ�ƌ��阋���ǻ��t���wϵ�����F�����Ї�����Ŀ�˵춨�Ԍ��Ĕ��ֻ���ʯ���_��AI�x���t�������I��ȫ��ƪ�¡�



































