









C114Ӎ 6��13����Ϣ����������Generative AI��Agentic AI�����M(j��n)�˳��У�Ҫ���^�m(x��)���ڡ��������ϣ��a(ch��n)Ʒ���g(sh��)��(chu��ng)�ºͮa(ch��n)�I(y��)���B(t��i)����ͬ����Ҫ��
������Generative AI�r(sh��)�����A��֮һ��AMD�@Ȼ���A�ø�����ƾ֣����@�������£�AMDԓ����ƾ֣�̫ƽ��r(sh��)�g2025��6��12������9:30��AMD����(hu��)��ϯ����ϯ��(zh��)�й��K���S��Lisa Su����ʿ��Advancing AI���(hu��)�Ͻo�����Լ��Ĵ𰸣��I(l��ng)�ȼ��g(sh��)+�_(k��i)�����B(t��i)+ȫ��������

���I(l��ng)�ȼ��g(sh��)���棬AMD���(zh��n)4000�|��Ԫ��AIӲ���Ј�(ch��ng)���ѽ�(j��ng)��(g��u)�����˰���CPU��GPU��DPU��FPGA���ڃ�(n��i)���������g(sh��)�ї��������ڿ��كr(ji��)ֵ���������_(k��i)�����B(t��i)���棬AMD���ڼӴ�(du��)ROCmܛ�����B(t��i)ϵ�y(t��ng)�Ľ��O(sh��)Ͷ�룬���°汾ROCm 7�ѽ�(j��ng)��������ʽAI������Ӌ(j��)�㹤��ؓ(f��)�d�������L(zh��ng)�����������(zh��n)�䣻��ȫ���������棬AMD���ڏ�(qi��ng)����߅�˅f(xi��)ͬ�ļ��� AI ƽ�_(t��i)Ը�������Ƴ������ИI(y��)��(bi��o)��(zh��n)��(g��u)���ġ��_(k��i)���ҿɔU(ku��)չ�ęC(j��)�ܼ�(j��)AI���A(ch��)�O(sh��)ʩ����Helios��AI�C(j��)��
���g(sh��)�I(l��ng)�ȣ�Instinct MI350ϵ��GPU��(sh��)�F(xi��n)35��������������
������İl(f��)���h(hu��n)��(ji��)�������_(t��i)�e늵�3nm��ˇ������1850�|���w�ܵ�Instinct MI350ϵ��GPU�o(w��)����������c(di��n)��
����AMD�vʷ�����ɹ��Įa(ch��n)Ʒ֮һ��Instinct MI350ϵ��GPU������CDNA 4�ܘ�(g��u)�������ܡ���(n��i)��������������GPU��(zh��)�І�Ԫ��(sh��)�����������ܵȷ��挍(sh��)�F(xi��n)��ȫ���M(j��n)��������ͨ�^(gu��)2.5D��3D���M(j��n)���b���g(sh��)��(sh��)�F(xi��n)�˾��w�ܵĸ����ܶȼ����Լ����õ���Ч���F(xi��n)��

���ܷ��ܣ�Instinct MI350ϵ��GPU֧�ֶ�N���c(di��n)���Ȕ�(sh��)��(j��)��ʽ������FP8��FP6��FP4��FP16��BF16�Լ�FP64�ȡ����ǰ���a(ch��n)Ʒ����AI�����õ��@������(qi��ng)��F(xi��n)P16�����_(d��)��18.5 PFlops��F(xi��n)P8��37 PFlops��F(xi��n)P6/FP4���_(d��)74 PFlops��MI350ϵ��GPU��ģ�ͅ���(sh��)̎��������7140�|������4.2�f(w��n)�|��������6�����܉���Ч�M����Z(y��)��ģ�ͺͻ�ό���ģ�͵�Ӗ(x��n)���c��������
��(n��i)��͎����������棬�@��AMD GPU�a(ch��n)Ʒ�^(q��)�e�����̵ď�(qi��ng)�(xi��ng)����Instinct MI350�a(ch��n)Ʒ�ϣ��@�N��(y��u)��(sh��)�õ����M(j��n)һ���ӏ�(qi��ng)�����(n��i)�������_(d��)����288GB HBM3E����������� 8TB/s���o(w��)Փ��Ӗ(x��n)��߀�����������ܫ@�ø��õ���������
��(du��)����˸����������ܶȵ�AIӲ���a(ch��n)Ʒ���ԣ�ɢ������DZ��Ҫ�挦(du��)�ġ�Instinct MI350ϵ��GPU����֧���L(f��ng)���ֱ��Һ���`�����ã��L(f��ng)��C(j��)�������ɲ���64��(g��)GPU��Һ��C(j��)�������ɲ���128��(g��)GPU���ṩ���_(d��)2.6 exaFLOPS �� FP4/FP6 ���ܡ�
��(d��ng)Ȼ����(du��)����K�Ñ����ԣ�TCO�ǂ�(g��)�����ĵ�Ԓ�}���K���S��ʿ��B�����Ӣ���_(d��)B200��AMD Instinct MI300Xϵ��GPUÿ��Ԫ��̎����Token��(sh��)���������_(d��)40%���ஔ(d��ng)�����\(y��n)�д��Z(y��)��ģ�ͣ�LLM���r(sh��)����λ�ɱ��µ�Ӌ(j��)��Ч������40%��

�����ڱ��η��(hu��)�ϣ�AMD߀������һ��Instinct MI400ϵ��GPU�����ԣ��������и��_(d��)40PF��20PF��FP4/FP8������������432GB HBM4��(n��i)�棬������������19.6 TB/s��ÿ��(g��)GPU�ęM��U(ku��)չ�������_(d��)��300 GB/s���M(j��n)һ����AIӋ(j��)�����١�

���H���������棬���W(w��ng)�j(lu��)�B�ӌ��棬AMD�Ƴ��˘I(y��)����֧�ֳ���̫�W(w��ng)(li��n)�ˣ�UEC�����Ե�AI���ܾW(w��ng)������AMD Pensando Pollara 400��ԓAI�����W(w��ng)��������ٺ�˾W(w��ng)�j(lu��)��(y��ng)�ö��O(sh��)Ӌ(j��)����(sh��)�F(xi��n)��400ǧ�ױ���ÿ�루Gbps������̫�W(w��ng)��ݔ���ʡ�
�_(k��i)�����B(t��i)���_(k��i)�l(f��)�����ϣ�ȫ��ROCm 7+�_(k��i)�l(f��)����
�_(k��i)�l(f��)�ߣ��_(k��i)�l(f��)�ߣ��_(k��i)�l(f��)�ߡ�
�ĕ�(hu��)�h�F(xi��n)��(ch��ng)ijλ���v���e���_(k��i)��(ch��ng)���У��҂���������w��(hu��)��ܛ�������B(t��i)����Ҫ�ԣ����@Ҳ��AMD���(j��ng)��(zh��ng)��(du��)��Ӣ���_(d��)���o(h��)�Ǻӡ�

��(du��)�ˣ��K���S��ʿ�o���Ĵ���ROCm 7���_(k��i)�l(f��)���ơ�AMD��(du��)ROCm��Ը����ͨ�^(gu��)һ��(g��)�_(k��i)�š��ɔU(ku��)չ�Ҍ�ע���_(k��i)�l(f��)�ߵ�ƽ�_(t��i)���������˽��i��(chu��ng)���ܡ���(j��)�K���S��ʿ��B���^(gu��)ȥһ���У�ROCmѸ�ٳ��죬������c�����_(k��i)Դ��^(q��)�ļ��ɡ����ROCm�(q��)��(d��ng)��ȫ������͵�һЩAIƽ�_(t��i)��֧��Llama��DeepSeek������ģ�ͣ��e�������µ�ROCm 7�汾�Ќ�(sh��)�F(xi��n)�˳��^(gu��) 3.5 ������������������
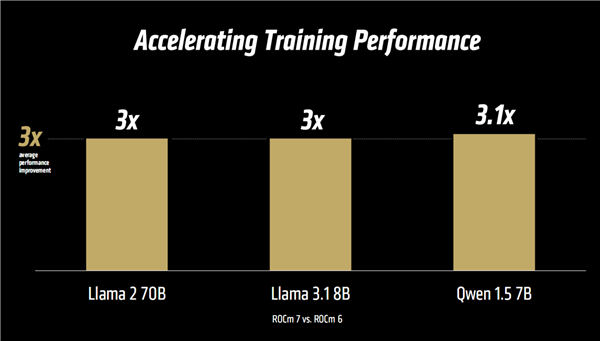
�S��AI��(y��ng)�Ï��о��D(zhu��n)����I(y��)���o(j��)����ROCmҲ��ͬ�����M(j��n)��ROCm��I(y��)��(j��)AI��һ��ȫ��ʽMLOps ƽ�_(t��i)�����_(t��i)ǰ���{��֧�ֳ��^(gu��) 180�f(w��n)��(g��)Hugging Faceģ�͵��_(k��i)�伴���w�(y��n)���Լ��ИI(y��)����(zh��n)�y(c��)ԇ�����룬ROCm�ṩ�����{(di��o)����Ҏ(gu��)������ͼ��ɵ��_(k��i)�伴�ù��ߣ��Ԍ�(sh��)�F(xi��n)��ȫ���ɔU(ku��)չ��AI����ROCm ���H�����s�������������I(l��ng)�_(k��i)�ŵ�AI���������K���S��ʿ�����v�Џ�(qi��ng)�{(di��o)��
�cROCm 7������(l��i)�ģ�߀�ИO���`���ԺͿɔU(ku��)չ�Ե�AMD�_(k��i)�l(f��)���Ʒ���(w��)��AMD�_(k��i)�l(f��)���Ʒ���(w��)�߂����O(sh��)�íh(hu��n)����֧���A(y��)���b��Docker�����ͳ�ɫ���`���ԡ���Day-0���B(t��i)��Instinct MI350ϵ��GPUϵ�y(t��ng)֧�����������ж�Ԫ���ĿɔU(ku��)չӋ(j��)���x�(xi��ng)�����_(k��i)�l(f��)���ṩ���M(f��i)�~�ȵȶ������c(di��n)��Ҳ�����f(shu��)���o(w��)Փ�ǺηN��(y��ng)�È�(ch��ng)����AMD�_(k��i)�l(f��)���ƶ��ṩ�˼��r(sh��)�_(k��i)ʼ�Ĺ��ߺ��`���ԣ��_(k��i)�l(f��)���ڲ������Ƶĭh(hu��n)����ጷ����a(ch��n)����
ȫ����������Helios��AI�C(j��)����(sh��)�F(xi��n)������ɡ�
�S����ģ��Ӗ(x��n)�������팦(du��)��������ı�ըʽ���L(zh��ng)�����y(t��ng)Ӌ(j��)��ܘ�(g��u)���y��֧��AI���g(sh��)�Ĵ��H�S�w��
����(ji��)�c(di��n)������AIDC����Scale Up�Į�(d��ng)ǰ�(y��u)�⣬ͨ�^(gu��)��(n��i)�����ٿ������B���܉���Ч֧�β���Ӌ(j��)���΄�(w��)������GPU֮�g�ą���(sh��)���Q�͔�(sh��)��(j��)ͬ�����s�̴�ģ�͵�Ӗ(x��n)�����ڣ������ܡ��ɱ����M�W(w��ng)���\(y��n)�S�ȷ��棬�ܞ��Ñ�(l��i)��(y��u)��(sh��)��

AMD�@ȻҲ�������@��(g��)څ��(sh��)����Advancing AI���(hu��)�ϣ�AMD������ʽ�Ƴ�Helios AI�C(j��)����A(ch��)�O(sh��)ʩ��������AMD EPYC��Venice�� CPU��Instinct MI400ϵ��GPU��Pensando ��Vulcano�� AI ���ܾW(w��ng)�������cROCmܛ���y(t��ng)һ������һ��(g��)��ȫ���ɵĽ�Q������AMD��Ŀ��(bi��o)�dz����_���Ǿ��Ǵ��조The World��s Best AI Rack Solution����
�ĬF(xi��n)��(ch��ng)��¶�Ĕ�(sh��)��(j��)��(l��i)����Helios AI�C(j��)�ܿ��ݼ{���72�KMI400ϵ��GPU��������260TB/s��HBM4��(n��i)�濂?c��)��?1TB��������1.4PB/s�����C(j��)���ܣ�Helios AI �C(j��)�ܿɸ��_(d��) FP8 1.4EFlops ( 140 �|�|��ÿ�� ) ��FP4 2.9EFlops ( 290 �|�|��ÿ�� ) ��
�����K���S��ʿ���v�ģ�AMD��Ψһ�߂�ȫ�渲�w��(sh��)��(j��)���ġ�߅�����K���O(sh��)��˵���AI�����Ĺ���(y��ng)�̣�����֧��ȫ��AI�����Ӳ������cܛ����(sh��)�������^(gu��)ȥ�������У�AMD EPYC������(w��)��CPU�Ј�(ch��ng)�ό�(sh��)�F(xi��n)�˳��^(gu��)18���ķ��~��������ԭ��(l��i)��2%������40%��1Q25�����҂���ȫ���������ţ��ڸ��Ӳ�����韵�AI�r(sh��)�����ڡ��I(l��ng)�ȼ��g(sh��)+�_(k��i)�����B(t��i)+ȫ���������ļӳ��£�AMD����(hu��)ӭ��(l��i)��һ݆���L(zh��ng)�� 


































