




C114Ӎ �����r�g5��21����Ϣ��������Light Reading��һƪ�������ᘌ�Ӣ���_ARC-Compact���Ƴ��c�����Ј�Ӱ��M���˷�����
�M���Ј�������ޣ�Ӣ���_��δ�ŗ�������ИI�N��AIоƬ�ćLԇ�����^�@��GPU���^�ƺ������D���еͶ��Ј������������Ƴ���RAN��Q�����������ˌ�AI�ď��{������f������Ӌ��C��ż溣܊�ٌ�������Grace HopperоƬ�M��һ�Һ��A������ͧ����ô���հl����ARC-Compact�t����һ�����ú��������ܾ����Ľ����ʹ�ֻ��
ȥ��l���Ĵ��dGrace Hopper�����mGrace Blackwell��ARC��������Ҫ��������ʽRAN��C-RAN��������\�I����ּ��ͨ�^�ͽ���������֧�ζ���վ�\�С���ȫ���Ƴ���ARC-Compact����ֲ�ʽRAN��D-RAN����վ�����OӋ���@һ�ܘ��D׃����ȫ��׃���g�����c����ģ�͡�

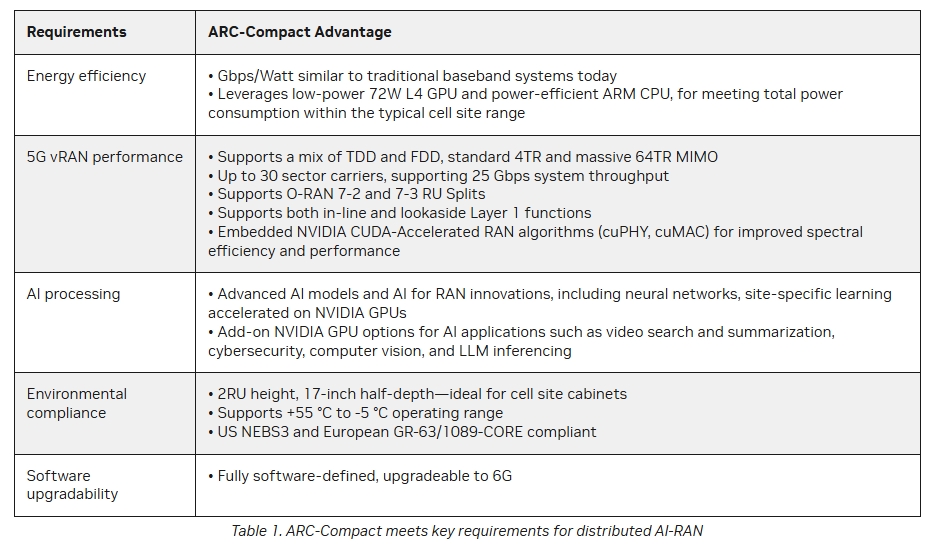
�D��Ӣ���_ARC-Compact�aƷ�D��
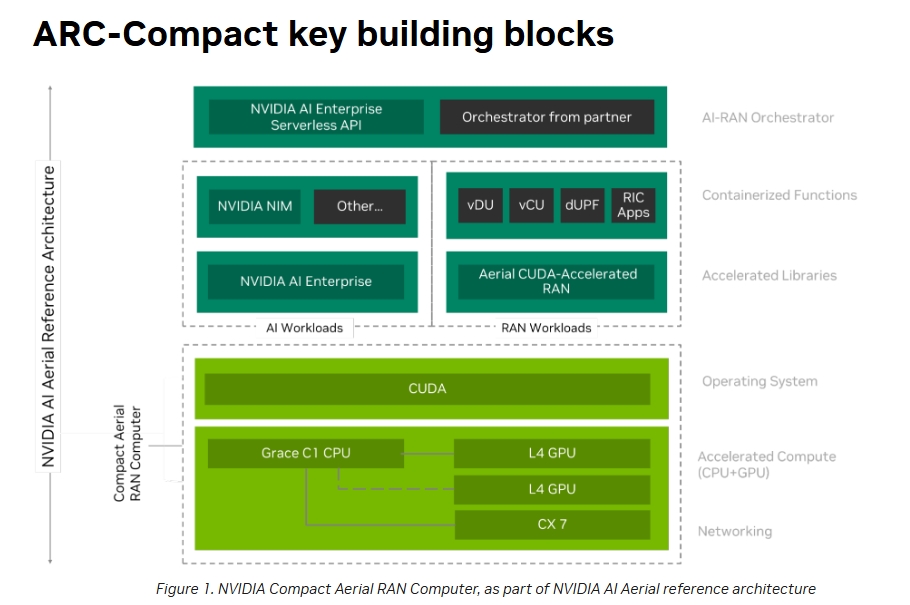
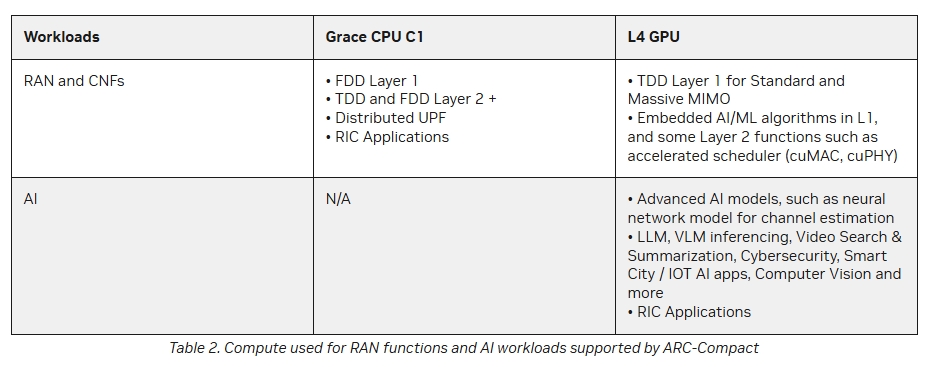
ARC-Compact�ĺ��ĽM���ǻ���ܛ�y����Arm�ܘ���Grace CPU��L4 Tensor Core GPU�����^��Hopper��Blackwell GPU��ԓ��Q���������p�������m����һЩ߅��ҕ�l̎���������΄գ����o�����δ��Z��ģ��Ӗ����ߏ���AI�\�㡣
�ڹٷ����g�����У�Ӣ���_��ARC-Compact�����顰���ԃr�ȡ�����Ч���Ľ�Q�������m���ڡ��͕r��AI����ؓ�d�cRAN���١���������L4 Tensor Core������Ҳ���ܳ������H����ǰ�Ј��������ޣ��H������RAN�O���̿��ܲ���ԓ���g�������Pע���c���A����Grace CPU��������GPU��
CUDA�ܘ����M����
�@�����O���̞����������Z�����c�������������ь�̓�M��RAN��vRAN�����g�M��Ͷ�Y��ԓ���g��ͨ��CPU�����5G�W�j�г�Ҋ�Č��ü����·��ASIC����Ӣ���_�����AI-RAN���@һ��������M�������h����CPU����̎��Ӌ�㏊���^�͵Ĺ���ؓ�d��ͬ�r����GPU����Layer 1�ġ���������������Layer 1��RANܛ�����Ќ����YԴ�ܼ��Ͳ��֡�
��ǰ�Ć��}���ڣ����������O���̾�δչ�F������Ӣ���_�yһӋ���O��ܘ���CUDA��������GPU�M��RAN�_�l�ď�����Ը���������c���Ǹ��A���ڲ��á���·��lookaside����vRAN�ܘ���ԓ�����錍�FӲ�������ԣ�����������Ȍ�ܛ��������CPU�\�С��ڬF�в����У��HLayer 1�еĸ�ؓ�d�΄ա���ǰ��m�e��FEC����ʹ��Ӳ����������
�����ű�ʾ����ԇ�h���У����Ӣ�ؠ�x86�ܘ�CPU������ܛ���������ļ�����ֲ��Graceƽ�_���@��ζ��������K����GPU�M���κ�RANӋ�㣬Ҳ�H����FEC̎��������ͬ����Graceƽ�_�M��ܛ���yԇ������������_��ʾ�����]����Layer 1��������������CPU�o���ṩ��������r������Ҫ������������ԓ��˾����ͨ�^�]����Light Reading��ʾ�����S�����g���M����CPU�Ѿ߂�֧�������������������҂��AӋ��ʹ�]�Ѓ�������Ҳ��֧��������������
�Z�����t�����菽����vRAN�YԴ����Ͷ����ܘ�������Layer 1����������Marvell Technology����Ӣ���_����ԓ��˾���J�D��CUDA�ܘ�����ȫ�،����a���Z�����ƄӾW�j�I�ռ��Fؓ؟��Tommi Uitto�ڽ���3��MWC�����_�����g��ʾ����������\�I�̲���GPU�M������AI��������t���]�б�Ҫ�M�д���ؘ��_�l��
�����@�N��r�£���Ӌ�㌢����Layer 1֮��Ĺ���ؓ�d����ôʹ��Layer 1������Ҳ�͟o�P�oҪ�ˡ��������rָ��������K���҂�ϣ����GPU��Ҳ���FLayer 1�����ڴ�֮ǰ���Z������Ӣ���_���g���Pע�c�����ܾ۽��ڌ�Grace����Layer 1���ϵĹ���ģ�K��
���K߅��Ӌ����O��
����f��Grace BlackwellоƬ����AI�������P�I�M����������Ŕ����������y��������ôARC-Compact���y�����@һ��ɫ�ˡ�ί����ԣ�����P������\�I�̿��ԏij���Ҏģ�Ʒ����̣�hyperscaler���c��������������I���ղ���ı�����c�ṩAI �������ղ����Fӯ���Ę���������Ќ��H���@ ��������ԇ�D����߅��Ӌ�����һ�·Lԇ��
�����B����\�I������������ȱ�����ġ�Omdia�����_չ��һ��{�飬ԃ�����L���J��δ�������AI̎�팢�l���ں�̎���H17%�����L�ش��ǻ�վ�c�м~վ�c������6%�x�������ęC���cǰ��վ�c��ռ�ȸ��_43%���������𰸞�K���Ñ��O�䡣����\�I���ƺ�̎�ڽK���O���chyperscaler�Ʒ���֮�g�ğo�˅^���������^�ں��ߵ�Ψһ�������ڸ��͵ľW�j�r�ӡ�
�z�����ǣ�����һ���е�Ҏģ�ć��ҁ��f���ǷN��Ҫ����վ�c����֧�εij��͕r�ӷ�����������㡣Omdia����ϯ������Kerem Arsal������ڂ����e�е�һ�������ָ����AI-RAN������ؓ������Ŀǰ���h���䃞�ݡ������⣬hyperscaler��߅��Ӌ�㼰��������Pϵ���dȤ�������ˣ�����ԭ���������̘Iģʽδ�ؕ��o߅��Ӌ�㎧����ô��؈��������Q������\�I����߅��Ӌ�㷽��������δչ�F�������f�����IJ���rֵ����
�S���I�猦Ӣ�ؠ�δ��ǰ�����ɑ]���أ�Grace�ij��F�@��ǡ����r����ǰ��Ӣ�ؠ���vRAN CPU�I���Ψһ�x����RAN���������C����ܛ���ɽ������ĵ���x86�cArm�ܘ�֮�g�M���w�ƣ��t��־�����ь��F��Ӳ�����ͬ�r��CPU���ܵij��m�������L���H���������ďS�̘�������Ӣ���_CEO�S�ʄ�����ȥ��9�±�ʾ����CPU�o������ASIC�Ĺ���ؓ�d̎����������
Kerem Arsalָ������AI̎���ܘ����Į�ǰ��GPU����ĵ��ΑB�������ܸ�����CPU�Aб�����⣬���w���ԣ�ģ���p����څ���@�����O������̎���P�IAI����ؓ�d�Ŀ����������������� �@һڅ���@Ȼ�c�S�ʄ��A�ڱ������Y��




