




C114Ӎ �����r(sh��)�g5��21����Ϣ��������Light Reading��һƪ����(b��o)����ᘌ�(du��)Ӣ���_(d��)ARC-Compact���Ƴ��c�����Ј�(ch��ng)Ӱ��M(j��n)���˷�����
�M���Ј�(ch��ng)������ޣ�Ӣ���_(d��)��δ�ŗ�������ИI(y��)�N��AIоƬ�ćLԇ�����^(gu��)�@��GPU���^�ƺ������D(zhu��n)���еͶ��Ј�(ch��ng)�����������Ƴ���RAN��Q�����������ˌ�(du��)AI�ď�(qi��ng)�{(di��o)������f(shu��)������Ӌ(j��)��C(j��)��ż溣܊�ٌ�������Grace HopperоƬ�M��һ�Һ��A����(j��)��ͧ����ô���հl(f��)����ARC-Compact�t����һ�����ú�(ji��n)�������ܾ���(ji��n)�Ľ�(j��ng)��(j��)�ʹ�ֻ��
ȥ��l(f��)���Ĵ��dGrace Hopper�����m(x��)Grace Blackwell��ARC����(w��)����Ҫ��������ʽRAN��C-RAN��������\(y��n)�I(y��ng)����ּ��ͨ�^(gu��)�ͽ���(sh��)��(j��)����֧�ζ���վ�\(y��n)�С���ȫ���Ƴ���ARC-Compact����ֲ�ʽRAN��D-RAN����վ�����O(sh��)Ӌ(j��)���@һ�ܘ�(g��u)�D(zhu��n)׃����ȫ��׃���g(sh��)�����c��(j��ng)��(j��)ģ�͡�

�D��Ӣ���_(d��)ARC-Compact�a(ch��n)Ʒ�D��
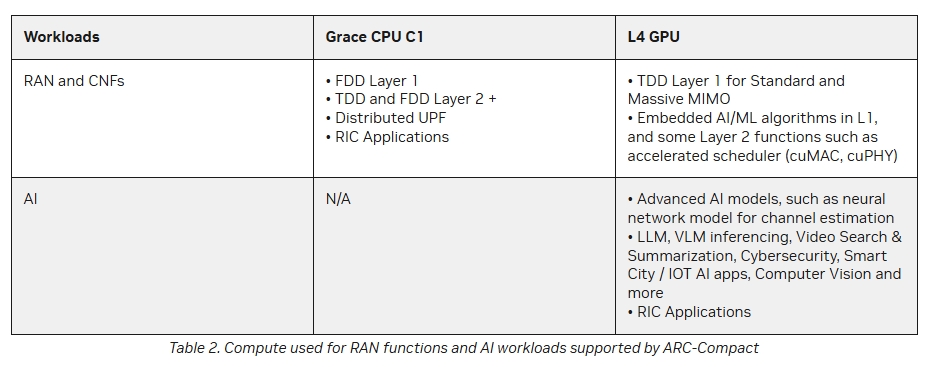
ARC-Compact�ĺ��ĽM���ǻ���ܛ�y����Arm�ܘ�(g��u)��Grace CPU��L4 Tensor Core GPU�����^��Hopper��Blackwell GPU��ԓ��Q���������p����(j��)���m����һЩ߅��ҕ�l̎���������΄�(w��)�����o(w��)�����δ��Z(y��)��ģ��Ӗ(x��n)����ߏ�(qi��ng)��AI�\(y��n)�㡣
�ڹٷ����g(sh��)�����У�Ӣ���_(d��)��ARC-Compact�����顰���ԃr(ji��)�ȡ�����Ч���Ľ�Q�������m���ڡ��͕r(sh��)��AI����ؓ(f��)�d�cRAN���١���������L4 Tensor Core������Ҳ���ܳ�����(sh��)�H����(d��ng)ǰ�Ј�(ch��ng)��(j��ng)��(zh��ng)���ޣ��H������RAN�O(sh��)���̿��ܲ���ԓ���g(sh��)�������P(gu��n)ע���c(di��n)���A����Grace CPU��������GPU��
CUDA�ܘ�(g��u)���M(j��n)����
�@�����O(sh��)���̞����������Z�����c�������������ь�(du��)̓�M��RAN��vRAN�����g(sh��)�M(j��n)��Ͷ�Y��ԓ���g(sh��)��ͨ��CPU�����5G�W(w��ng)�j(lu��)�г�Ҋ�Č��ü����·��ASIC����Ӣ���_(d��)�����AI-RAN���@һ��������M(j��n)�������h����CPU����̎��Ӌ(j��)�㏊(qi��ng)���^�͵Ĺ���ؓ(f��)�d��ͬ�r(sh��)����GPU����L(zh��ng)ayer 1�ġ���(n��i)(li��n)������������Layer 1��RANܛ�����Ќ����YԴ�ܼ��Ͳ��֡�
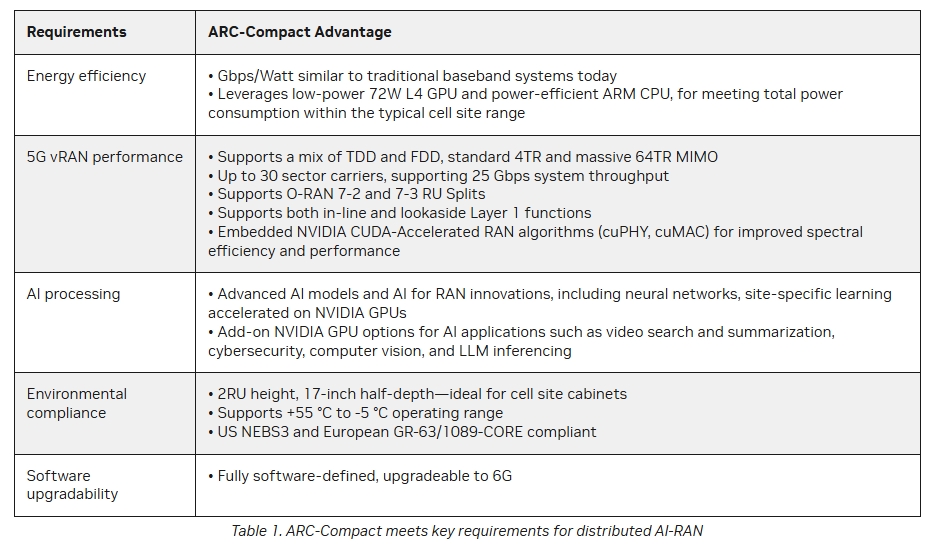
��(d��ng)ǰ�Ć�(w��n)�}���ڣ����������O(sh��)���̾�δչ�F(xi��n)������Ӣ���_(d��)�y(t��ng)һӋ(j��)���O(sh��)��ܘ�(g��u)��CUDA����(l��i)����GPU�M(j��n)��RAN�_�l(f��)�ď�(qi��ng)����Ը���������c���Ǹ��A���ڲ��á���·��lookaside����vRAN�ܘ�(g��u)��ԓ�����錍(sh��)�F(xi��n)Ӳ����(d��)���ԣ�����������Ȍ�ܛ��������CPU�\(y��n)�С��ڬF(xi��n)�в����У��HLayer 1�еĸ�ؓ(f��)�d�΄�(w��)����ǰ��m�e(cu��)��FEC����ʹ��Ӳ����������
�����ű�ʾ����ԇ�(y��n)�h(hu��n)���У����Ӣ�ؠ�x86�ܘ�(g��u)CPU������ܛ����(j��ng)�����ļ�����ֲ��Graceƽ�_(t��i)���@��ζ��������K����GPU�M(j��n)���κ�RANӋ(j��)�㣬Ҳ�H����FEC̎��������ͬ����Graceƽ�_(t��i)�M(j��n)��ܛ���y(c��)ԇ������������_��ʾ�����]����Layer 1��(n��i)(li��n)������������(d��ng)CPU�o(w��)���ṩ��������r(sh��)������Ҫ��(n��i)(li��n)����������ԓ��˾����ͨ�^(gu��)�]����Light Reading��ʾ�����S�����g(sh��)���M(j��n)����CPU�Ѿ߂�֧������(qi��ng)�������������҂��A(y��)Ӌ(j��)��ʹ�](m��i)�Ѓ�(n��i)(li��n)������Ҳ��֧��������������
�Z�����t�����菽����vRAN�YԴ����Ͷ���(n��i)(li��n)�ܘ�(g��u)������Layer 1��������(l��i)��Marvell Technology����Ӣ���_(d��)����ԓ��˾���J(r��n)�D(zhu��n)��CUDA�ܘ�(g��u)����ȫ�،����a���Z�����Ƅ�(d��ng)�W(w��ng)�j(lu��)�I(y��)��(w��)���F(tu��n)ؓ(f��)؟(z��)��Tommi Uitto�ڽ���3��MWC�����_�����g��ʾ����������\(y��n)�I(y��ng)�̲���GPU�M(j��n)������AI��������t���](m��i)�б�Ҫ�M(j��n)�д���ؘ�(g��u)�_�l(f��)��
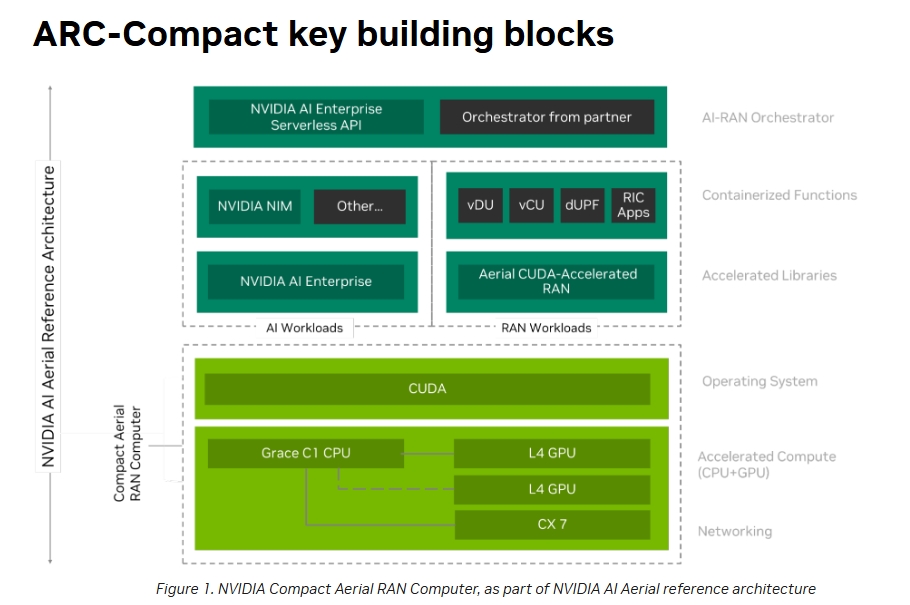
�����@�N��r�£���Ӌ(j��)�㌢����Layer 1֮��Ĺ���ؓ(f��)�d����ôʹ��Layer 1������Ҳ�͟o(w��)�P(gu��n)�oҪ�ˡ�������(d��ng)�r(sh��)ָ��������K���҂�ϣ����GPU��Ҳ��(sh��)�F(xi��n)Layer 1�����ڴ�֮ǰ���Z������(du��)Ӣ���_(d��)���g(sh��)���P(gu��n)ע�c(di��n)�����ܾ۽��ڌ�Grace����Layer 1���ϵĹ���ģ�K��
��(f��)�K߅��Ӌ(j��)����O(sh��)��
����f(shu��)��Grace BlackwellоƬ����AI�������P(gu��n)�I�M����������Ŕ�(sh��)��(j��)�������y��������ôARC-Compact���y�����@һ��ɫ�ˡ�ί����ԣ�����P(gu��n)������\(y��n)�I(y��ng)�̿��ԏij���Ҏ(gu��)ģ�Ʒ���(w��)�̣�hyperscaler���c������(sh��)��(j��)������I(y��)����(w��)����ı�����c(di��n)�ṩAI ��������(w��)����(sh��)�F(xi��n)ӯ���Ę�(g��u)��������Ќ�(sh��)�H���@ ����(l��i)����ԇ�D����߅��Ӌ(j��)�����һ�·Lԇ��
�����B����\(y��n)�I(y��ng)����������(du��)��ȱ�����ġ�Omdia�����_չ��һ�(xi��ng)�{(di��o)�飬ԃ��(w��n)���L���J(r��n)��δ��(l��i)�����(sh��)AI̎�팢�l(f��)���ں�̎���H17%�����L�ش��ǻ�վ�c�м~վ�c(di��n)������6%�x�������ęC(j��)���cǰ��վ�c(di��n)��ռ�ȸ��_(d��)43%���������𰸞�K���Ñ��O(sh��)�䡣����\(y��n)�I(y��ng)���ƺ�̎�ڽK���O(sh��)���chyperscaler�Ʒ���(w��)֮�g�ğo(w��)�˅^(q��)���������^�ں��ߵ�Ψһ��(y��u)��(sh��)���ڸ��͵ľW(w��ng)�j(lu��)�r(sh��)�ӡ�
�z�����ǣ���(du��)��һ��(g��)�е�Ҏ(gu��)ģ�ć�(gu��)�ҁ�(l��i)�f(shu��)���ǷN��Ҫ����վ�c(di��n)����֧�εij��͕r(sh��)�ӷ���(w��)��������㡣Omdia��(j��)��ϯ������Kerem Arsal������ڂ����e�е�һ��(ch��ng)���(d��ng)��ָ����AI-RAN������ؓ(f��)������Ŀǰ���h(yu��n)���䃞(y��u)��(sh��)�������⣬hyperscaler��(du��)߅��Ӌ(j��)�㼰��������P(gu��n)ϵ���dȤ�������ˣ�����ԭ���������̘I(y��)ģʽδ�ؕ�(hu��)�o߅��Ӌ(j��)�㎧��(l��i)��ô��؈�(b��o)�����������Q������\(y��n)�I(y��ng)����߅��Ӌ(j��)�㷽��������δչ�F(xi��n)�������f(shu��)�����IJ���r(ji��)ֵ����
�S���I(y��)�猦(du��)Ӣ�ؠ�δ��(l��i)ǰ�����ɑ]���أ�Grace�ij��F(xi��n)�@��ǡ����r(sh��)����ǰ��Ӣ�ؠ���vRAN CPU�I(l��ng)���Ψһ�x����RAN����(y��ng)�����C����ܛ���ɽ������ĵ���x86�cArm�ܘ�(g��u)֮�g�M(j��n)���w�ƣ��t��(bi��o)־�����ь�(sh��)�F(xi��n)��Ӳ�����ͬ�r(sh��)��CPU���ܵij��m(x��)������(du��)�L(zh��ng)���H���������ďS�̘�(g��u)������(zh��n)��Ӣ���_(d��)CEO�S�ʄ�����ȥ��9�±�ʾ����CPU�o(w��)������ASIC�Ĺ���ؓ(f��)�d̎����������
Kerem Arsalָ������AI̎���ܘ�(g��u)���Į�(d��ng)ǰ��GPU����ĵ��ΑB(t��i)�������ܸ���(qi��ng)��CPU�Aб�����⣬���w���ԣ�ģ���p����څ��(sh��)�@�����O(sh��)������̎���P(gu��n)�IAI����ؓ(f��)�d�Ŀ����������������� �@һڅ��(sh��)�@Ȼ�c�S�ʄ��A(y��)�ڱ������Y�� 




������ؔ(c��i)�a(ch��n)���_�ܓp���O(sh��)��Ո(q��ng)��һ���յ���(l��i)늣������� ��")