




�S����ģ�ͼ��g���w�ٰlչ����ģ�B���ܣ���ͬ�r����D������ֵ�AI��Ҳӭ����ͻ�ơ�Ȼ�������ܱ��F������ҕ�X-�Z��ģ�ͣ�Vision-Language Models��VLMs���������������������ŵ�VLMs���ձ���څ�����Û�Ć��}�����dͨӍ�ܵ�DeepSeek R1-Zero�Ć��l���Ƴ���Curr-ReFT ��Curriculum Reinforcement Fine-Tuning��Ӗ����ʽ�����p������VLMsӖ���ɞ�����ģ�͎����˃����Ӗ��˼·��
�Ć�ʾ�����£�Curr-ReFT���Q��
DeepSeek R1-Zeroͨ�^���M�������ԃ�����Group Relative Policy Optimization, GRPO�����@�������˴��Z��ģ���ڏ��s�����΄��еı��F��չʾ��ģ�ͻ�������푑����Ҹ��M�ĝ��������dͨӍ��Ƚ��b������Y�϶�ģ�B�΄��������������Сģ�ͺ�Ӗ��������Curr-ReFT��ʽ��
Curr-ReFTӖ����ʽ�ďͬFR1-Zero�ڶ�ģ�B���W�����ϵ�Ӗ�����l�F���A�����������ޡ����Q�@һƿ�i�����dͨӍ��đ���£���ԭ����ه�бO���{��Ӗ�����̣�ȫ���D���ԏ����W������ĵķ�ʽ�����F��Ӌ��Cҕ�X��CV������ģ�B�΄��е�ȫ�������ܣ���Чͻ�ơ�Superficial Pattern Matching������ģʽƥ�䣩�����}��
�Mһ��ᘌ��p��VLM������������������Brick Wall��ƿ�i���������y�}��Curr-ReFT���롰�n��ʽ�����W�������ԣ�ͨ�^�����y��ѭ��u�M�����A���΄��OӋ������ģ�����l���흓�ܡ�ͬ�r���Y�ϻ��ھܽ^�ɘӵĸ��|���{�C�ƣ����F��ģ�������ij��m������
Curr-ReFTӖ����ʽ�������p����VLMӖ���ăɴ���ļ��g
1. �n�̏����W������ѭ��u�M�������y�}Curr-ReFT���b���n�ý̌W�� �������y���Ľ̌W��������s�΄ղ�֞������A�Σ�������ģ�͵�������
����һ�A�Σ���Ԫ�Q�ߌW����ҕ�X����ģ�͏���ε��΄����֣��H��ش��ǡ������ٽ������A��ҕ�X����ͺ����������������磬AIģ���܉��Дࡰ�@���O�����
���ڶ��A�Σ�����x��W�����J֪�S�w
�S��ģ���M���x���}�A�Σ���Ҫ�Ķ����x������x���_�𰸣��@һ�A�μȿ��Q��������Ҳ����ģ�͌W���ֱ漚����ͨ�^呟��^�����ͼ���������AIģ����������������ˮ�����Ă����
�������A�Σ��_��ʽ�ش���˼�S�X�� ��K��ģ�͌��挦�_���Ԇ��}����Ҫ�����D���������Ϣ���������@�r��ģ�͵ľC�����������õ����呟�����K������"�@�����v����ʲô����"��
�@һ�ӌ��f�M�Ī���C�ƴ_����ģ���܉����������m��Խ��Խ���s���΄գ�����������^����|�y�}�����FӖ������������r��
2. �ܽ^�ӱ����Ҹ��M�����������x�����m���҃����������������s����������ͬ�r���pʧģ�͵Ļ����Z�Լ��ܣ����dͨӍ߀�����˻��ھܽ^�ɘӵ����Ҹ��M�C�ơ�
�����ȣ��҂��������M��GPT-4-O���骄��ģ�ͣ���ģ�����ɵĻش��M��ȫ��λ�u�֣������ʴ_�ԡ�߉�ԡ���ʽ�������ȣ���ֻ���u�ֳ��^85�ֵĻش�ű����x������
���������@Щ���|���ӱ��M��һ������������, �@Щ�߷ִ𰸳ɞ�ģ�����ҌW���ą�����ͨ�^���������e�`���������F��ģ���������m������
�@�N�����_��ģ���ڲ����M����ͬ�r��ʼ�K���������Ļ��A���������������^�M��ijЩ�����΄ն�Ӱ����w���F��
Curr-ReFT������C��Сģ�ͣ�������
����ȫ���u��Curr-ReFT��Ӗ��������Ч�����҂��xȡ��Qwen2.5-VL-3B��Qwen2.5-VL-7B�ɂ����Aģ���M����C�����Y���@ʾ��Curr-ReFT���@�ɂ�ģ���ϵı��F���@����Խ��ԭ�л����������ڶ������_�����yԇ�г�Խ�˸���Ҏģ��26B��InternVL-26B����32B��Llava-Next-32B��ģ�͡�
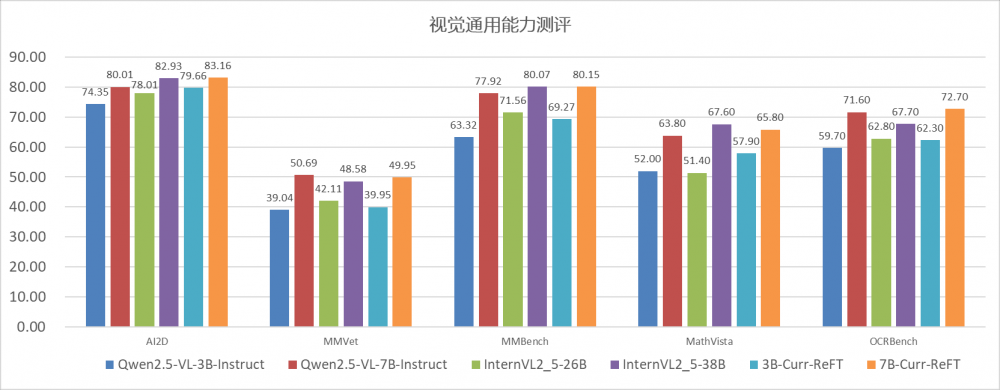
�����������S����Curr-ReFT-3Bģ����AI2D���W����yԇ�Мʴ_���_83%�����ԭģ�͵�74%�����@����������Խ�˶���΄���26B��InternVL-26B����32B��Llava-Next-32B���Ĵ�ģ�ͱ��F��
������������������Qwen2.5-VL-7B���A�ϣ�Curr-ReFT�Mһ�����������S�w��ҕ�X�z�y�ʴ_�ʏ�89.8%������92.2%������΄՜ʴ_�ʏ�71.5%������73.1%�����P�I���ʜyԇ��Ҳȡ���@��ͻ�ƣ�MMVet��29.95%������36.78%��MathVista��58.6%������92.2%����
�@һϵ�Д�������C����Curr-ReFT���H�m��Сģ�͡����������������߂��ģ�͡����΄յ�ͨ���m��������
���g�rֵȫ��ጷţ�Сģ�ͣ������
���dͨӍ�����аl��Curr-ReFTӖ����ʽ���{������ă��ݣ���С��ҕ�X�Z��ģ���ڸ��ҕ�X�ı��΄����ṩ�ˈԌ����ϣ����w���c������
���I�ȼ��g�����dͨӍ�����аl��Curr-ReFTӖ����ʽ��ʹС��VLMs�ڸ��ҕ�X�ı��΄���չ�F��Խ�������ͷ���������
����Ч���ã�ԓ���g����ͨ�����ķ��A��Ӗ���;ܽ^�ɘӲ��ԣ���ʹ���YԴ���ĭh���£�Ҳ�܌��F���������ٵ�ģ�̓�����
���V�����È������oՓ�����ܽK�ˡ�߅��Ӌ��ƽ�_߀���������ģ����dͨӍ���@헄��¾��ܞ�͑��ṩ��Ч���ͳɱ���VLMs��Q������
�y�ք��£����Lδ��
���dͨӍʼ�K������ǰ�ؼ��g�ij��m̽���cͻ�ƣ���Curr-ReFT�@һ����Ӗ����ʽ��ȼ�����AISӖ��ƽ�_�����H����������p����VLM��Ӗ�����̣����@��������Сģ�͵������c����������δ�������dͨӍ���y�����B��飬��ͬ��չҕ�X�Z�����ܵ���߅�磬�x��ǧ�а٘I�~�����Ч�����ջݵ������r����
�_Դ���d朽ӣ�
���a��https://github.com/ding523/Curr_REFT
������https://huggingface.co/datasets/ZTE-AIM/Curr-ReFT-data
ģ�͙��أ�https://huggingface.co/ZTE-AIM/3B-Curr-ReFT
ģ�͙��أ�https://huggingface.co/ZTE-AIM/7B-Curr-ReFT