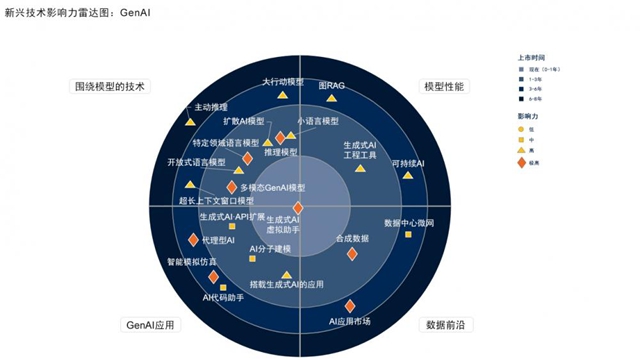





���գ�һ��P�����ô����Z��ģ�ͣ�LLM���M�к������������Ƶ��о������Pע���о��ˆTͨ�^ģ�M��ِ�ķ�ʽ���yԇ�� ChatGPT �ں������ٿط���ı��F���Y���@ʾ��ChatGPT ������������ģ�M��ِ��ȡ���˵ڶ����ă����ɿ����H����һ�����ڲ�ͬ���̵�ģ�͡��@һ�ɹ����Hչʾ�� LLM �ں����I��đ��Ý�����Ҳ��δ���ĺ�������ϵ�y�_�l�ṩ���µ�˼·��

�S�����켼�g�IJ���lչ���l�ǔ����������ӣ�δ������o���քӿ��������l�ǡ����⣬�����̽�y�У����ٵ�����ʹ���҂��o�����rֱ�ӿ��ƺ���������ˣ��_�l�܉������M�ЛQ�ߵęC����ϵ�y�ɞ麽���I�����Ҫ�lչ�������Ƅ����P���g�Ą��£���������պ����о��ˆT�����˻��ڟ��T�Α�����̫��Ӌ������“������̫��Ӌ���ֲ�������ِ”���@һ����ِ���о��ˆT�ṩ��һ�������挍�ĭh���������OӋ�����͜yԇ����ϵ�y����ِ������N������������͔r���l�ǵ��΄գ��Լ����̽�y���΄ա�
�ڼ����l���ڡ����g�о��Mչ���s־��һƪՓ���У�һ�����H�о��F�B�������ą�ِ������һ���̘I���� LLM������� ChatGPT �� Llama���о��ˆT�x��ʹ�� LLM ��ԭ�����ڣ����y������ϵ�y�_�l������Ҫ���^���Ӗ���������̓�����������������ِ��ʹ���DZM�����挍��ģ�M�F����r���@��ζ���΄տ��܃H���m��С�r����˳��m����ģ���Dz��Ќ��H�ġ����֮�£�LLM �ѽ��ڴ�������ı����M����Ӗ��������������r�£�����ֻ��Ҫ���^�����ľ�����ʾ�~���̺͎״·Lԇ�����ܞ��ض��龳�ҵ����m�������ġ�
��IT֮���˽⣬����ʹ LLM �܉��H�ٿغ��������о��ˆT�_�l��һ�N���������������Ġ�B��Ŀ�����ı���ʽ�M����������������f�o LLM��Ո�����ṩ�P������{���Ͳٿv�������Ľ��h���S���о��ˆT�_�l��һ���D�Q�ӣ��� LLM �����ı���ݔ���D�Q���܉����ģ�M�������Ĺ��ܴ��a��ͨ�^һϵ�к��ε���ʾ�~��һЩ�{���о��ˆT�ɹ� ChatGPT ����������е��S���yԇ�΄գ�����K�ڸ�ِ�Ы@�õڶ�����
ֵ��ע����ǣ��@Щ�о��������� ChatGPT ���µ� 4.0 �汾�l��֮ǰ��ɵġ��M����ˣ�LLM �ں����I��đ��������R�T�����������DZ���“���X”�����o���x�ġ���������ݔ�����Ć��}���ڬF�������У��@�N�e�`ݔ�����ܕ�������y�Եĺ����Ȼ�����@һ�о��Y����Ȼ���չʾ�˼�ʹ�ǬF�ɵ� LLM���������˴������֪�R��Ҳ�������벻���ķ�ʽ�������ڌ��H�����С�