




C114Ӎ 5��24����Ϣ�����Ԍ���5��23�գ���CIOE�Ї��ⲩ���cC114ͨ�žW���e�k��2024�Ї����|���lչՓ�����Ĉ�������AI�r�����������Ĺ⻥���g��څ�ݡ���ӑ���ɹ��e�У����|�⻥�ܘ���ꐬb�ڕ��Ϸ������P�ڡ�������Ӌ���W�j�еĹ⻥�B�������}�l�ԡ�

���|�ڸ�����Ӌ��W�j�I�����^�磬���m�ڶ������H�������ؓ������˴�����Ͷ�룬���È����漰�������]�㷨�����ܿͷ���AI���u���U��������ֱ���ȵȡ�
����W�j�ؓ�һ��֞������ľW�j����һ�ǽ���/�惦�W�j����Ҫ���FCPU֮�g�Ļ��������Ӌ��W�j����Ҫ�M��GPU���c�����IJ��Ѕfͬ��
���w����������W�j���ڹ⻥�B��Ҫ����Ҫ�����������棬�������ͳɱ��͵��ӕr��
��ģ�K�c�����Pϵ
�����·�������棬����Ҫ���F����GPU�cGPU֮�g���ж�·��ͨ�ţ���Ҫע�┵����ݔ�^�����·��������r����Ӌ�㹝�c�Ȳ�����һ��ɲ���C2C Full mesh�ķ�ʽ���B�����ʿ��_����GB/s��
��Ҫ���F��ͬGPU���ڵ�ͨ�ţ��tҪͨ�^PCle�c�W���B�ӣ����M�д����D�����M��ͨ�^��ģ�K��Ӌ��W�j���F��˿��B�ӡ���ˣ���ǰ�S���S�Ҿ����ᳫ��Wݔ��/ݔ��(OIO)����ʽ����ͻ�Ƹ��ٻ���ƿ�i���@Ҳ�Ǯ��µ�һ���lչ����
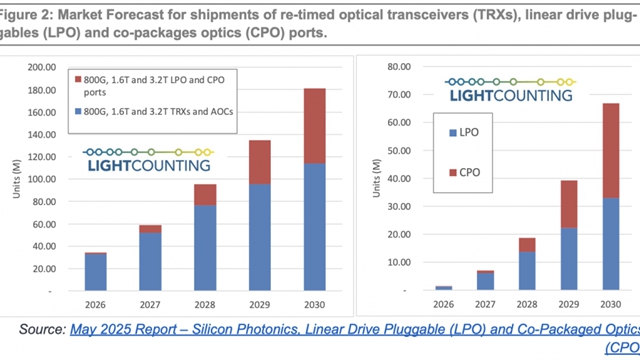
�ھW�j�O��/��ģ�K�������M���棬��ǰ����W�j��Ҫ�������50G Serdes�����Q�C��ģ�K����ģ�K����x��t��200G/400G�Ȟ��������ι��c�����_��51.2T�r���������W�j����չ�Ե�Ҫ���ȥ�x��ͬ���ؓ���ͣ�������һЩ�S�ҕ��x��64x800G OSFP�����ȏS�҄t����128x400G QSFP 112�ķ��b�������߮a�I���ͨ�õġ�
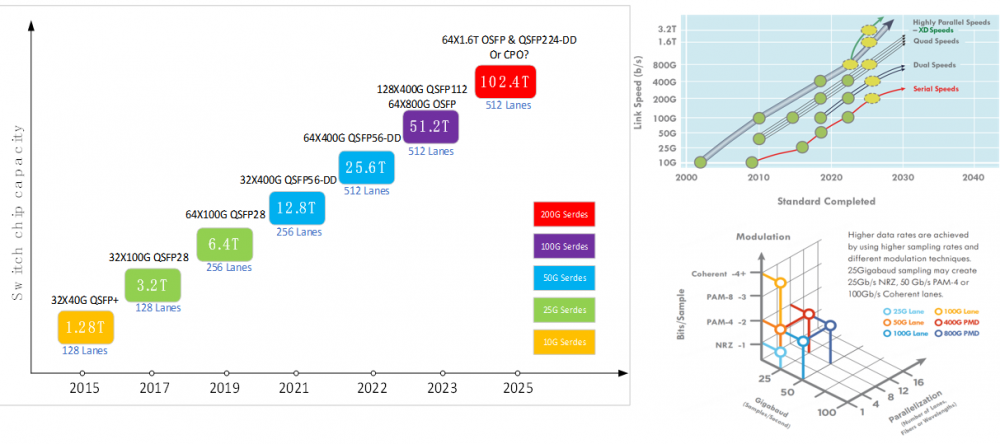
��δ����оƬ���Q�����_��102.4T���ɲ�ι�ģ�K��Ȼ����֧�ָ��ܶȴ������Ĺ⻥�B���ã������x��64x1.6T OSFP��QSFP224-DD����CPOҲ�ǟ��T�Ľ�Q����֮һ����Ҫ�^�m��Q�ɿ��ԵĆ��}��߀Ҫ��Q���O�����еĿɾS�o�Ԇ��}��
��ν��⻥�B�ɱ���
�ڽ��⻥�B�ͳɱ����}�У�������Ӽ��g�ǝ��ڵĽ��ɱ�����֮һ����Ⲣ����ȫ�µļ��g�����͔������đ��ö����DZ��^�µĮaƷ����ǰ112G per laneģ�K�Ĺ�������μ����������������S�ң���˹���ģ�K���ԓ��˽��룬�Դ��ƹ����o�����}��
�e���ģ�K�ǿ��Ը��w��Q2km�ԃȵ����Д������đ��È�����Ҫ�ģ���˾��|Ҳ���M���������J�C�ȹ��������Ų��õČ���Ҳ�������IJ����¾W�j�С�
����ֱ��ģ�KLPO/LRO��ǰҲ�DZ��^���T�đ��÷�����112G per lane�r����������ASIC������������ԣ����Ԍ���ģ�K���p������ȥ��DSP��CDR�IJ��֣��M���ɽ���ģ�K�ď��s�̶ȣ����_�����ͳɱ���Ŀ�ġ�
����Ҳ���R��һЩ������������c����ͨ�Ć��}��Ҫ���]ASICоƬ�����֧����r����ͬ�S���g����r�����fģ�K����ͨ����r�ȵȆ��}��
߀���ݻ��ɳ��m�ԵĆ��}ҲҪ���]�M������112G�ѿ�֧��LPO������lչ��224G�ȣ���Ҫ����LPO�Ƿ�֧�ֵĿ������ˡ�
����W�j���ӕr���}
�ڵ��ӕr���棬��Ҫ���F���w�fͬ���\�㱣�ϣ���ͬ��Ӌ�㹝�c�g��GPU�ӕr���}�ݱؕ�����\��Ч�ʣ���ô��Щ����ͨ���������ӕr�أ�
�����ǻ��څf�h��GPU�ľW�j�������InfiniBand��IB���ąf�h��ʽ�^�࣬�ڔ�����ݔ�п��@�^CPU�ą��c�����F�˲�ͬӋ�㹝�c�gGPU����֮�g������ͨ�������p���˻��څf�h��ͨ���ӕr��

���ڂ��y��̫�ąf�h���tҪCPU���뵽ͨ�������^�̣�������ӕr�����^�L��
������W�j���õ�����һ���^�����еķ�������RDMA�������ɽ�����̫�f�h�ķ��b��RDMA�ăȺ˷��b�Mȥ���M�����F������̫�W���Oʩ�Ԍ��F�����ӕr��
��΄t���·�ӕr�����GPU�cGPU֮�g��ͨ��Ҫ���^leaf-spine�ܘ�����Ҫ�M�й���̖�D�Q�����F�����������^���и��h��Ҳ��Ȼ�a�����N��ͬ���ӕr��
���ڛQ���ģ�͵ĕr���У��Ƀ���헞��ģ�K�е���̖�֏͆�Ԫ���µ��ӕr����������ʽģ�͵��ӕr�У���Ҫ�ǔ�����ݔ�r�g���µ��ӕr�������������·���µ��ӕr���Hռ�ȘOС����ˣ��@�r��ϵ�y�ӕr�������������ʸ������У�Ҫ����ģ�Ͳ�ͬȥ�����ӕr�IJ�ͬ����
���ꐬb���Y�������^�ڂ��y��ͨ�W�j������W�j���������LҲ����Ѹ�٣��ͳɱ�����ه���¼��g��֧�Σ����⡢LPO/LRO�ȡ����⣬��ͬ��ģ�͌��ӕr��Ҫ���Dz�һ�ӵģ�Ҫ�����ķ���������^�e��