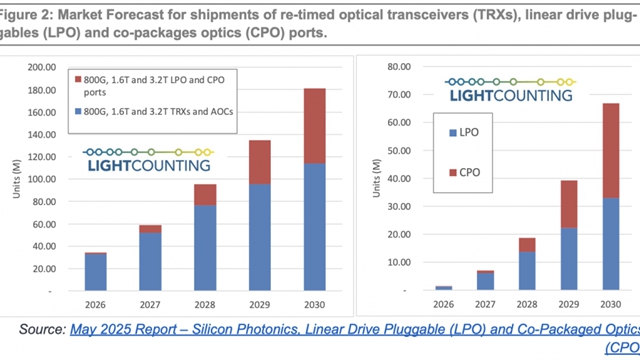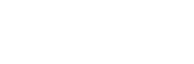





����ͨ�xǧ�� Qwen �F����գ�5 �� 26 �գ��l(f��)�� QwenLong-L1-32B ģ�ͣ������ׂ�ͨ�^�����W(xu��)��(x��)Ӗ(x��n)�����L�ı��龳����ģ�ͣ�LRM����
���߂��L�ı� DocQA ����(zh��n)�yԇ�У����F(xi��n)��Խ o3-mini �� Qwen3-235B-A22B ����Ş?z��i)��ͣ��c Claude-3.7-Sonnet-Thinking �ஔ(d��ng)��
QwenLong-L1-32B ģ���������c�����������Ĵ������֧�� 131072 �� tokens��ԓģ�ͻ��� QwenLong-L1 ����_�l(f��)�����������M�� GRPO��Group Relative Policy Optimization���� DAPO��Direct Alignment Policy Optimizatio���㷨���Y(ji��)�ϻ���Ҏ(gu��)�t�ͻ���ģ�͵Ļ�Ϫ����(sh��)���@��������ģ�����L�����������еĜ�(zh��n)�_�Ժ�Ч�ʡ�
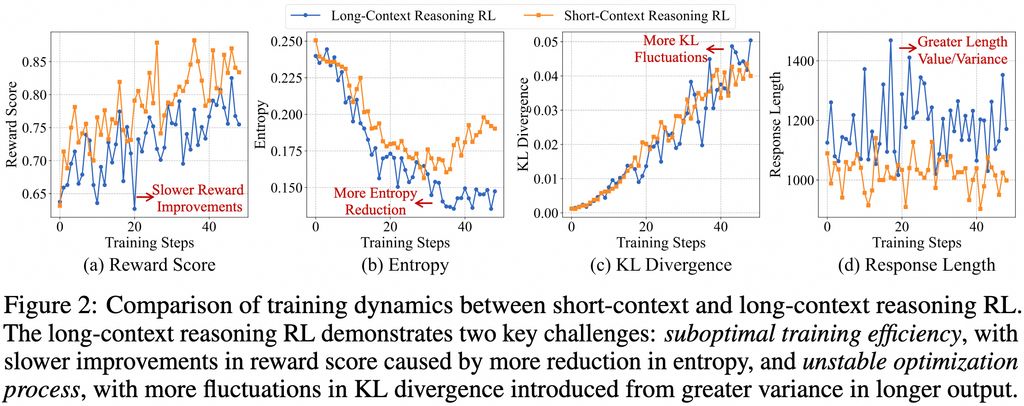
���w���ԣ��F��ڱO(ji��n)���{(di��o)��SFT���A�ν���һ����(w��n)���ij�ʼ���ԣ��S������n������(d��o)�ķ��A�Ώ����W(xu��)��(x��)���g(sh��)����(w��n)��������׃�����Y(ji��)���y�ȸ�֪�Ļ�ɘӲ��ԁ��������̽����
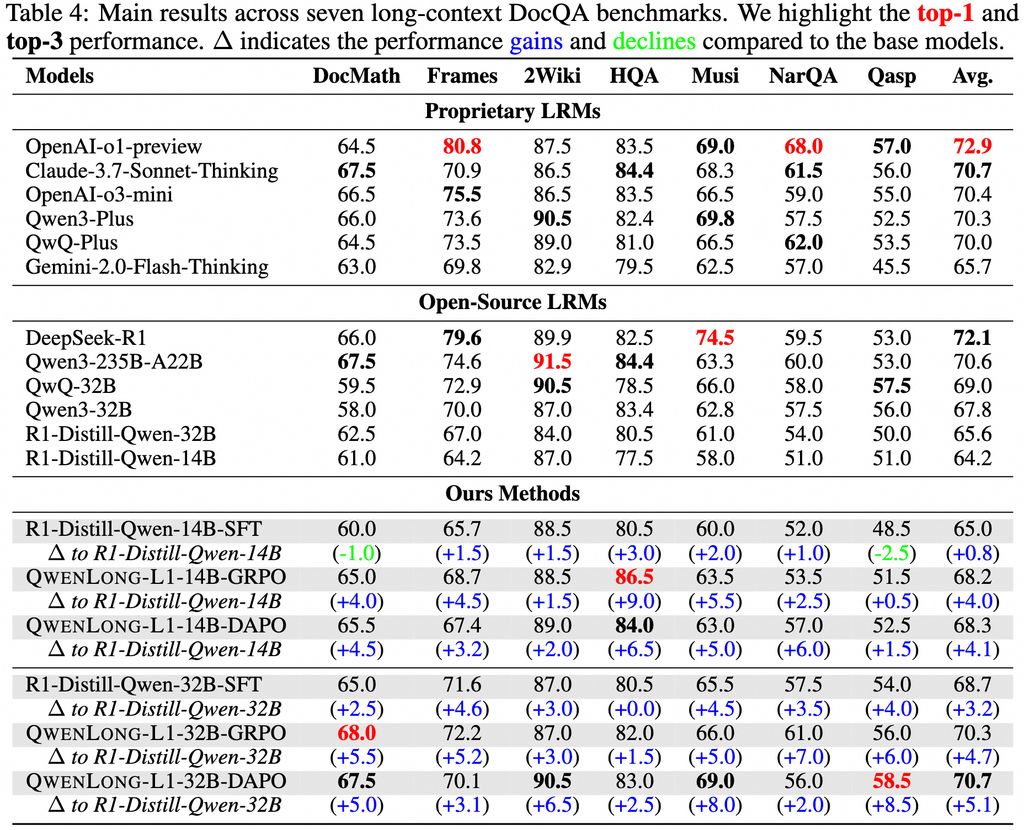
����ģ�ͱ���������߀�l(f��)����һ��ᘌ��L�ı����톖�}��������Q������ԓ���������Ă����ĽM��: �����ܵ� QwenLong-L1-32B ģ�͡����T��(y��u)����Ӗ(x��n)����(sh��)��(j��)������(chu��ng)�µď����W(xu��)��(x��)Ӗ(x��n)���������Լ�ȫ��������u���wϵ��